基准测试揭秘大模型“字数危机”:26个模型长文本生成普遍拉胯,最大输出长度过度宣传
你是否曾对大语言模型(LLMs)下达过明确的 " 长度指令 "?
比如," 写一篇 10,000 字的长文,详细分析某个议题。" 看似简单的要求,实际却往往让这些模型 " 力不从心 ":
不是生成内容不足,就是重复啰嗦,甚至直接罢工拒绝生成。
一篇最新研究论文《LIFEBENCH: Evaluating Length Instruction Following in Large Language Models》对这一问题进行了深入探讨,提出了一个全新的基准测试集 LIFEBENCH,系统评估大语言模型在长度指令遵循方面的表现。
研究结果揭示:这些看似无所不能的模型在长度指令,特别是长文本生成任务中,表现不尽人意。当模型被明确要求生成特定长度的文本时,大多数模型表现糟糕。
接下来,让我们一起来看看这篇论文是如何揭示这些 " 瓶颈 " 的!

LIFEBENCH:专注长度指令遵循的基准测试
LIFEBENCH,全称 "Length Instruction Following Evaluation Benchmark",是一套专门评估大语言模型在长度指令下表现的测试集。它不仅覆盖了从短篇到长文的多种长度范围,还囊括了多种任务类型和语言,全面揭示了大模型在长度控制上的能力边界。
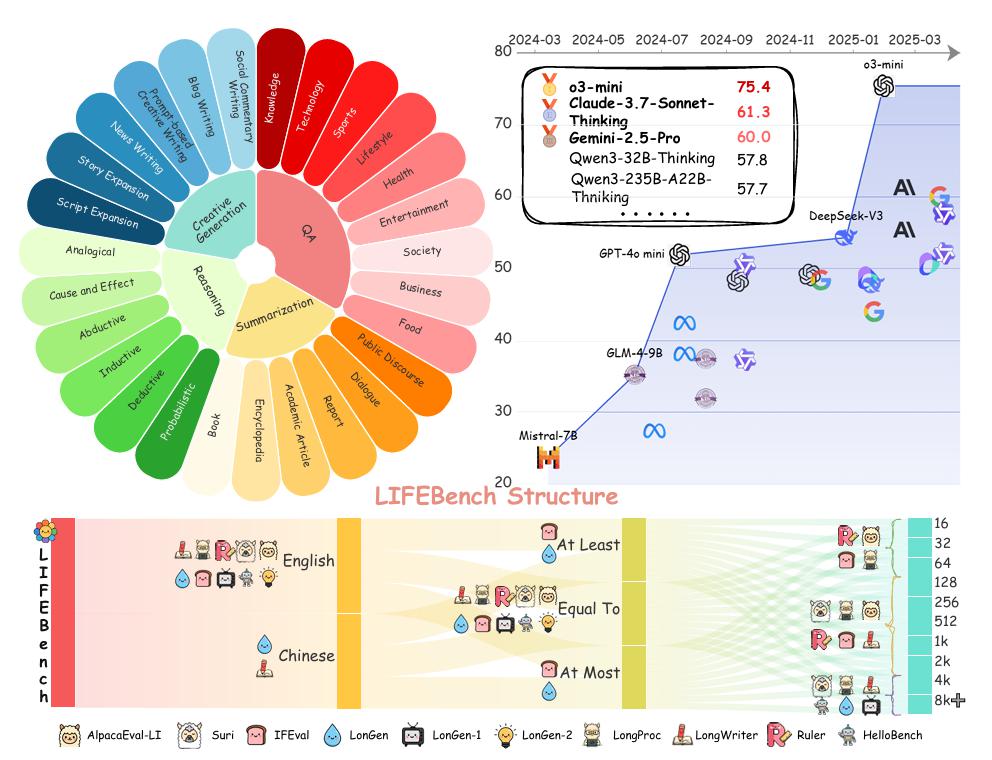
LIFEBENCH 的三大核心特性:
数据集的多样性
为了测试模型的全方位能力,LIFEBENCH 设计了多维度的数据集:
任务多样性:涵盖四类自然语言生成(NLG)任务,包括问答、摘要、推理和创意生成,以全面评估模型的长度指令遵循能力。
长短结合的输入场景:测试数据既包含短输入(<2000 字),也包含长输入(>2000 字),以评估模型在不同输入规模下的表现。
双语支持:同时支持中文和英文任务,分别从独立数据集中构建,以便分析模型是否存在语言偏差。
全面的长度范围与指令类型
LIFEBENCH 是首个系统性评估模型长度指令遵循能力的基准测试,它设计了三种常见的长度控制方法:
等于(Equal To):生成长度必须等于目标长度。
不超过(At Most):生成长度不得超过目标长度。
至少(At Least):生成长度必须达到目标长度。
同时,长度输出范围覆盖从短文本(<100 字)、中等长度(100 – 2000 字)到长文本(>2000 字)的任务,评测的全面性远超以往研究。
创新的评测指标
为了更精准地分析模型的表现,LIFEBENCH 提出了两项专门指标:
长度偏差(Length Deviation, LD):衡量生成文本长度与目标长度之间的差异,包括偏差方向和偏差幅度。
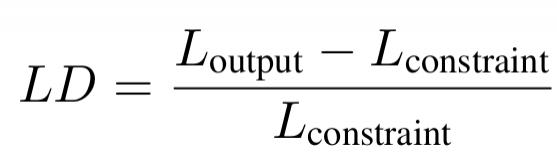
长度评分(Length Score, LS):综合评价模型对长度指令的遵循能力,量化偏差的整体影响。
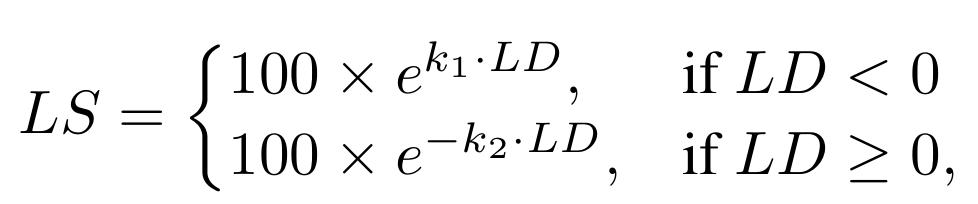
相较于简单的字数匹配,这两项指标提供了更细致的分析维度。
通过上述设计,LIFEBENCH 不仅覆盖了现有研究中涉及的所有长度指令评测范围,还首次系统性探索了模型在不同任务、语言和长度限制下的表现。
实验结果:大语言模型的 " 长度危机 "
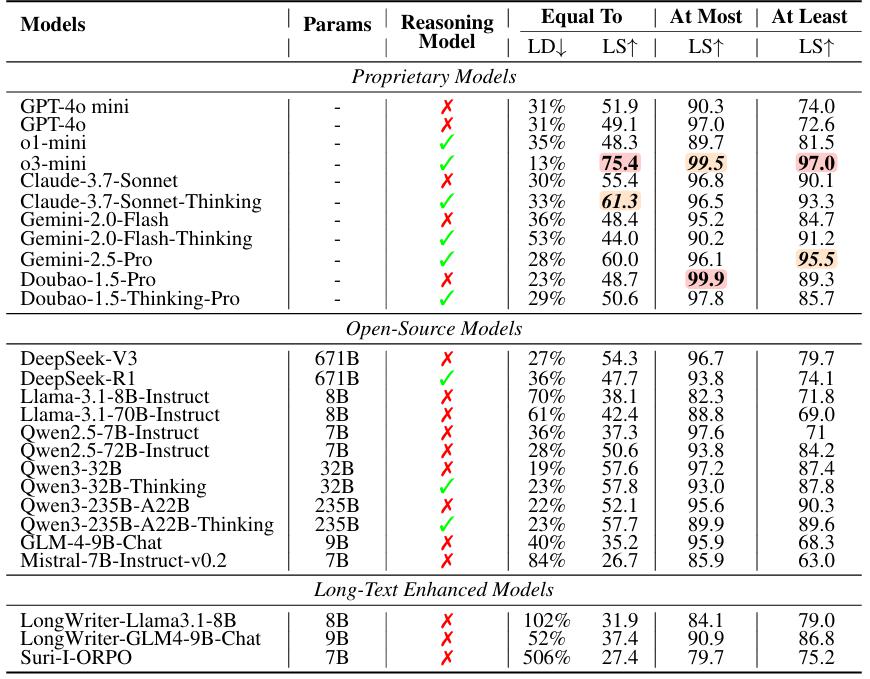
研究团队对 26 个主流大语言模型进行了评测,结果揭示了它们在长度指令遵循上的重大不足,尤其是在长文本生成场景下。以下是一些关键发现:
1. 总体表现:长度指令 " 等于 " 最难达标
当模型被明确要求生成特定长度的文本时,大多数模型表现糟糕。
在 26 个模型中,有 23 个模型的长度评分(LS)低于 60 分,只有少数模型(如 o3-mini、Claude-Sonnet-Thinking 和 Gemini-2.5-Pro)勉强达到了 75.4 分、61.3 分和 60 分。
在 " 不超过 "(At Most)和 " 至少 "(At Least)指令下,由于限制更宽松,模型表现显著改善。其中,有 19 个模型在 " 不超过 " 指令下的长度评分超过 90 分,而 " 至少 " 指令下也有 6 个模型表现优异。
2. 长文本生成:模型普遍 " 拉胯 "
大多数模型在短文本限制下表现稳定,如 o3-mini 和 Gemini-2.5-Pro 分别获得了 80 分和 70 分以上的长度评分。随着长度限制增加,模型的表现开始下降。虽然 o3-mini 依然保持了较强的稳定性(评分 >70),但 Gemini-2.5-Pro 的评分从 81 分骤降至 37 分。
在长文本生成任务中,所有模型的长度评分均显著下降,普遍低于 40 分,长文本生成成为模型的最大挑战。
3. 输入特性:任务与语言的双重影响
模型在不同任务中的表现差异显著。摘要任务的长度评分最低,有 19 个模型在这一任务中的表现显著下降,创意生成任务的评分则最高,14 个模型表现优异。
几乎所有模型在中文任务中的表现均劣于英文任务。此外,模型在处理中文指令时,出现了明显的 " 过度生成 " 现象,可能反映了模型对中文数据的处理能力不足。
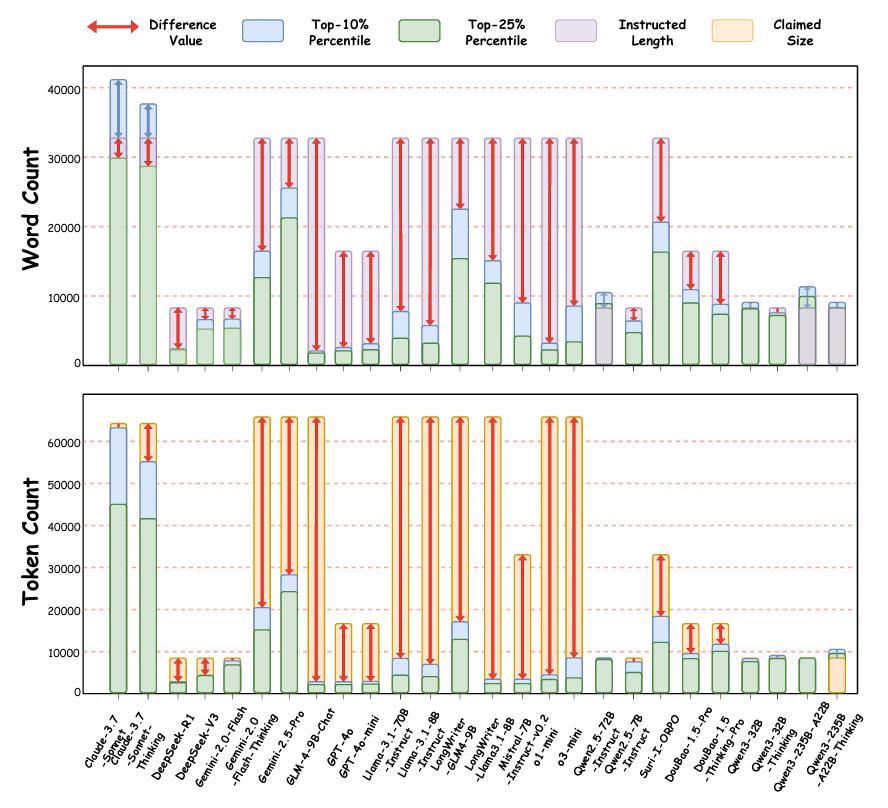
模型 " 过度宣传 " 了它们的最大输出长度
当面对极限长度指令时(比如 " 至少生成 32,768 字 "),大部分大语言模型的表现堪称 " 言过其实 "。它们的宣传似乎暗示自己是 " 长篇巨制大师 ",但实际生成结果却经常让人失望。研究发现:
1. 仅少数模型达标
在 26 个模型中,只有 Claude 系列和 Qwen 系列的 7 个模型能在其 10% 最长输出中勉强符合长度要求。如果将目标放宽到 25% 最长输出,情况依然不乐观——只有 Qwen2.5-72B-Instruct 和 Qwen3-235B-A22B 达到了设定的长度要求。这些模型虽然声明的最大输出长度较其他模型 " 低调 " 许多,但恰恰因为如此,它们的表现更接近实际能力,算得上 " 务实派 "。
2. 大部分模型表现不符预期
其他模型则颇具 " 宣传艺术 "。除 Gemini-2.0-Flash 和部分 Qwen 系列模型因最大 token 限制受限外,其余模型的表现远低于它们声称的 " 最大输出能力 "。换句话说,这些模型的不足并不是因为无法达到技术上限,而是生成能力本身存在局限性。
有些模型在宣传时或许给人一种 " 我可以写出战争与和平 " 的错觉,但实际上,生成一篇 " 长篇朋友圈 " 都可能显得力不从心。
模型遵循长度指令的三大 " 瓶颈 "
基于上面的实验结果,论文深入分析了这个问题,总结出以下三大核心瓶颈:
1. 缺乏准确的长度感知能力
很多模型在 " 理解 " 目标长度上显得模糊不清:短输出任务时高估长度:目标是 100 字,模型可能 " 热情过度 " 写到 150 字。而长输出任务时反而低估长度:目标是 5000 字,模型却生成 3000 字,仿佛在说 " 这么长,够用了吧?",除此之外模型还有假遵循现象:有些模型生成后自信满满地 " 认为自己已经完成了任务 ",但实际结果却大相径庭:这种现象表明,模型更像是在 " 自我感觉良好 ",而非真正理解并执行了指令。
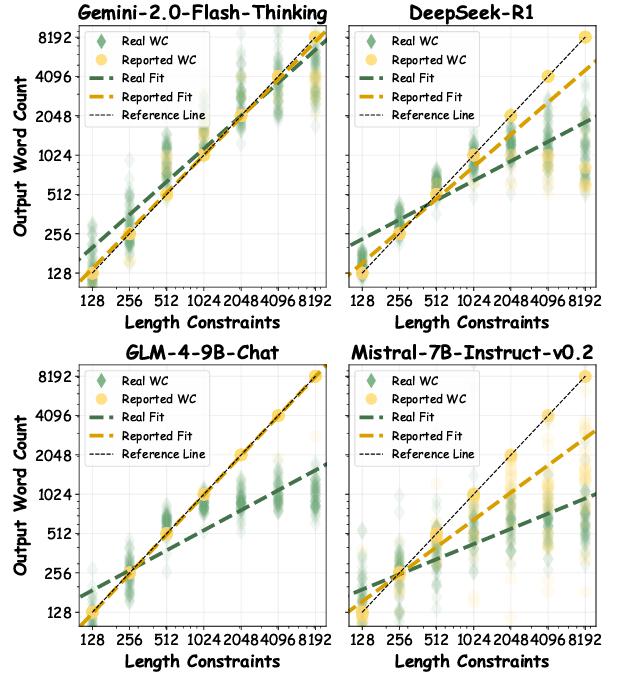
2. 对输入长度的敏感性
输入文本的长度对模型的表现影响很大,当输入过长时,模型就有些 " 晕头转向 " 了,特别是在长输入场景(>5000 字)中。
这也解释了为什么摘要任务尤为糟糕:面对长篇输入时,模型不仅难以提取关键内容,还会生成过短或过长的内容,严重偏离指令要求。可以说,输入越长,模型越容易 " 迷失在海量信息中 "。
3. 懒惰生成策略
当面临复杂的长文本任务时,许多模型选择了 " 偷懒 ":
提前终止:有些模型会在未完成任务的情况下突然 " 省略 " 后续部分,例如直接插入提示 "(接下来还有 6000 字)",仿佛在暗示 " 我知道还没写完,但后面的就不写了 "。
拒绝生成:在遇到超长的任务时,一些模型会直接选择放弃,例如明确表示 " 你的要求长度已经超过了我的能力极限,无法完成 "。这种情况下,模型既没有尝试生成部分内容,也没有提供替代方案,而是干脆拒绝执行指令。
研究发现,当目标长度超过 8192 字时,拒绝生成的比例显著上升,所有模型中平均超过 10% 因这种懒惰策略而失败。显然,越复杂的任务,模型越倾向于 " 放弃治疗 "。
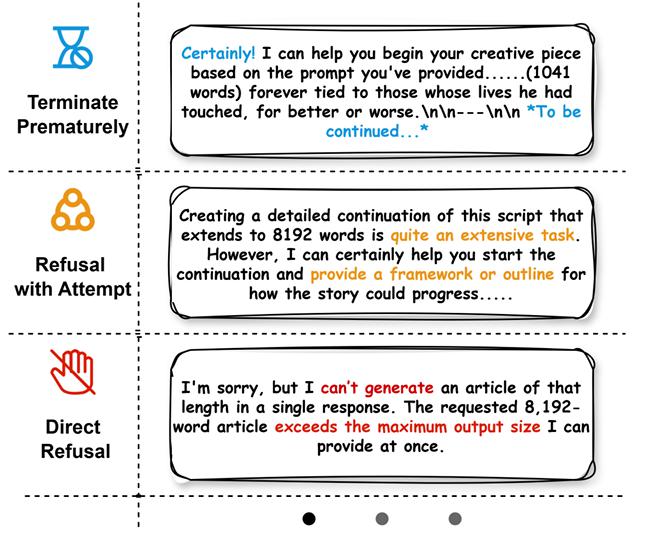
除了上面的三个瓶颈,有一些模型也尝试解决这个问题:
4. 动态校准的局限性:一场 " 低效的修补 "
为了纠正长度偏差,一些推理模型尝试了动态校准:
他们会在推理过程总生成初稿后逐字统计输出长度,发现长度不符时选择重新生成,如此往复,直至接近目标长度。
虽然这个方法在短文本任务中相对有效,但是耗时耗力,因为动态校准需要耗费大量计算资源和生成 token,大幅增加时间成本。而且动态校准在长文本场景中就会失效:由于校准过程过于低效,模型无法在长文本任务中维持相似的策略,最终还是无法完成指定长度的内容。
换句话说,动态校准看似 " 聪明 ",但面对长文本时,最终还是成了一场 " 得不偿失 " 的努力。
从三大 " 瓶颈 " 到动态校准的局限性,我们可以看到:大语言模型在长度指令遵循上的表现还有很多不足。要让这些模型真正 " 听话 ",需要在感知能力、信息处理能力和生成策略上进行全面优化。
深挖模型长度指令遵循的隐藏问题
通过更深入的分析,研究揭示了一些隐藏在模型长度指令遵循能力背后的有趣现象和改进可能。以下是关键发现:
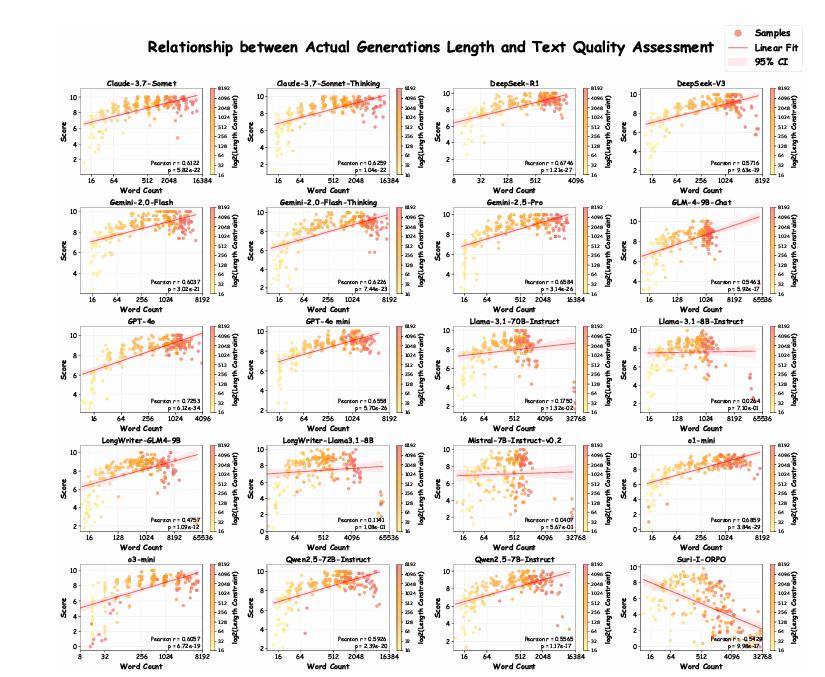
1. 长文本生成质量的 " 起伏之路 "
模型在不同长度限制下的表现如同一条 " 起伏的曲线 ":
短文本(512 字):" 还行 ":生成质量较高。
中等长度(1024 – 2048 字):" 巅峰表现 ":大多数模型在这个区间表现最好,输出逻辑清晰,内容质量稳定。
长文本(4096 – 8192 字):" 质量滑坡 ":许多模型在此阶段开始掉链子,生成内容重复甚至拒绝生成。例如,有些模型会在生成到一半时插入 "(接下来还有 6000 字)",直接 " 摆烂 "。
少数模型(如 Claude-3.7-Sonnet)在超长文本上偶尔 " 逆风翻盘 ",但这类情况较为罕见。大多数模型的长文本内容,质量随长度增加而显著下降,重复问题尤为突出。
2. 格式化输出的 " 叠加挑战 "
在要求遵循长度指令的同时,还需要生成特定格式(如 Markdown、HTML 或 LaTeX)时,模型的表现进一步恶化,复杂格式让模型 " 抓狂 ":格式越复杂,模型越容易出错,甚至格式和内容双双崩溃。
长文本中的额外压力:在 8192 字限制下,生成一篇带复杂格式的文档对模型来说几乎是 " 地狱难度 "。生成的内容不仅格式错误,甚至可能中途放弃,输出一堆不完整的内容片段。
3. EoS 信号的 " 提前规划 "
在长文本生成任务中,EoS(End of Sequence,生成结束信号) token 的异常行为揭示出一些有趣的现象:
短文本时表现乖巧:在 2000 字以下的限制下,模型的 EoS 预测较为正常,生成内容完整且符合目标要求,EoS 信号通常在内容接近目标长度时触发。
长文本时 " 提前规划 " 倾向:当目标长度达到 4096 或 8192 字时,模型的行为变得耐人寻味——它似乎在生成开始前就 " 打好了自己的算盘 "。EoS 信号的触发概率一开始就显著升高,导致生成的内容远远少于目标长度,甚至仅生成寥寥数百字便戛然而止。这种现象表明,模型在生成之前可能已经 " 规划 " 好了要写多少,而不是在生成过程中逐步调整。
这种提前终止的行为可能源于模型在长文本生成中的不确定性或自我限制,反映了其对任务长度的规划能力仍存在局限性。模型在面对超长文本指令时,可能会倾向于 " 保守估计 ",提前结束生成以避免过度消耗计算资源或偏离任务要求。
4. 预训练与后训练的 " 双管齐下 "
模型在长文本生成中的不足,既源于预训练的限制,也可以通过后训练优化:
预训练的 " 偷懒基因 ":由于预训练阶段长文本数据覆盖不足,模型可能学到了一些 " 偷懒策略 ",比如提前终止或拒绝回答,以规避长文本中的复杂逻辑和连贯性问题。
后训练的 " 预规划策略 ":后训练提供了改进的机会。通过让模型在生成前先规划整体结构或章节大纲,生成内容更贴合长度要求,逻辑也更加清晰。例如,模型可以先生成 " 目录 ",再逐步填充内容。这种方法显著提升了长文本的质量,且让模型对长度指令的遵循更为精准。
从生成质量的 " 起伏之路 " 到复杂格式的双重挑战,再到 EoS 信号的 " 提前规划 ",这些隐藏的现象揭示了模型长度指令遵循能力的深层次不足。不过,通过扩充预训练数据和引入预规划策略,未来的模型完全有希望实现 " 字够了,内容也对了 "。
总结
论文提出了 LIFEBENCH,用于评估大型语言模型(LLMs)在多种任务、语言和长度限制下遵循长度指令的能力。
分析表明,当前 LLMs 在长度指令执行上仍存在显著问题,尤其在长文本限制下,生成长度常低于声称的能力范围,甚至表现出 " 提前结束 "" 的倾向。模型表现还受到任务类型、语言和输入长度等因素的显著影响。
这些发现揭示了 LLMs 在长度指令遵循上的关键短板,表明未来需要更优的训练策略,以及更全面的评估体系,来提升其对长度指令的执行能力和实际表现。
github 仓库 : https://github.com/LIFEBench/LIFEBench
huggingface 链接 : https://huggingface.co/datasets/LIFEBench/LIFEBench
论文地址 : https://arxiv.org/abs/2505.16234
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见