边缘AI正当时,Imagination押注GPU的“AI进化”
导语
在人工智能推理日益走向边缘计算的浪潮中,Imagination 推出全新 E 系列(E-Series)GPU IP,以革命性的 "AI+ 图形 " 深度融合架构,回应边缘侧对低功耗、高灵活性与强算力的多重需求。通过架构创新、算力扩展、功耗优化以及软件生态配套,E 系列试图重新定义 " 边缘 AI 计算 " 的边界,并提供一条兼顾灵活性与高效性的技术路径。
边缘 AI 进入加速期,GPU 迎来转型窗口
当前边缘侧 AI 推理正以前所未有的速度增长。从市场应用端来看,自动驾驶、智能手机、工厂设备、甚至消费级机器人,都在逐步脱离云端,开始在本地完成图像识别、路径规划、语音交互等智能化任务。
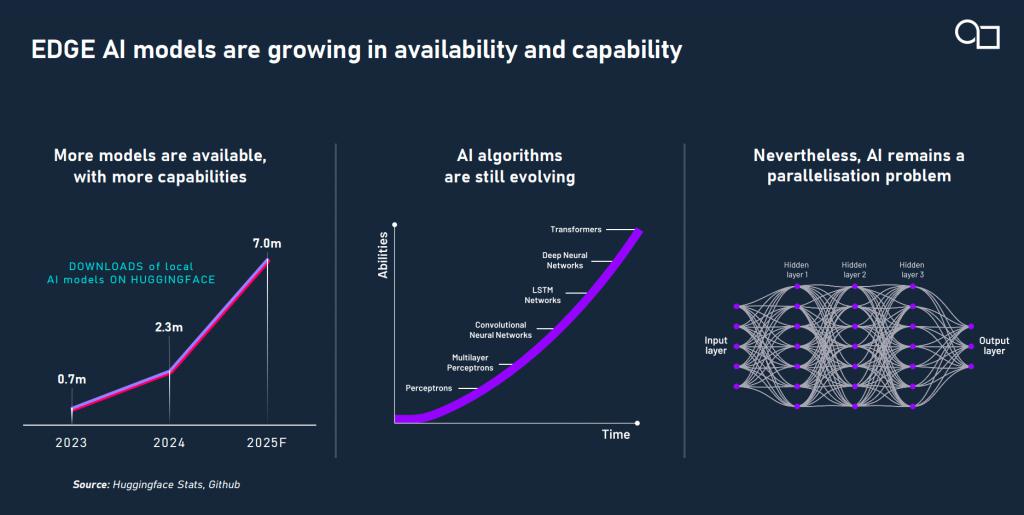
图源:Imagination(下同)
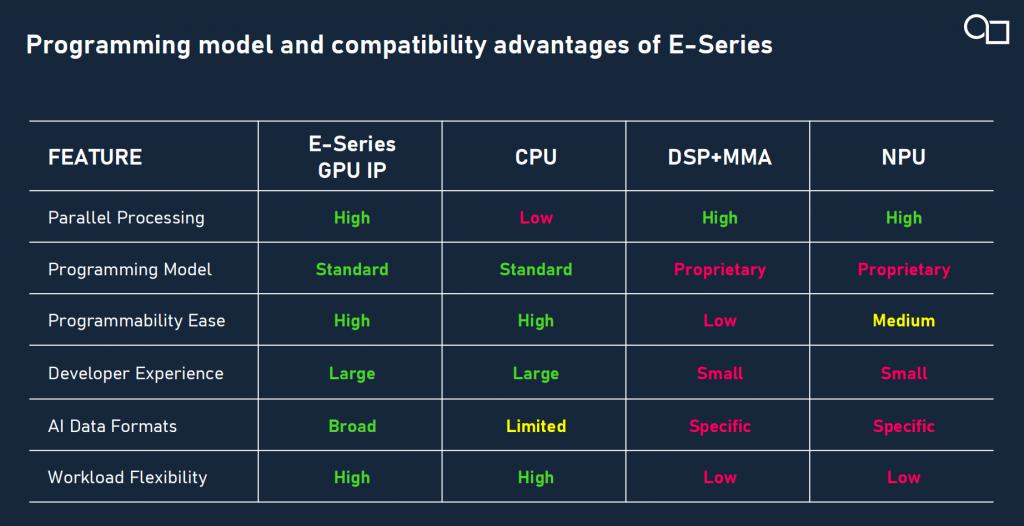
传统处理器架构在应对边缘 AI 时各有优劣:CPU 灵活,但处理并行任务吃力;NPU 强大,却在应对新模型、新算子时捉襟见肘;GPU,特别是可编程的通用 GPU,恰好介于两者之间。但传统 GPU 并非为 AI 推理而生,其架构仍有诸多优化空间。在当前 AI 工作负载逐年变化的情况下,AI 硬件系统仍需要一定程度的灵活性和通用加速能力,以确保设备的未来适用性。而 Imagination 的 E 系列 GPU IP 正是在这个夹缝中开辟了一条新路。
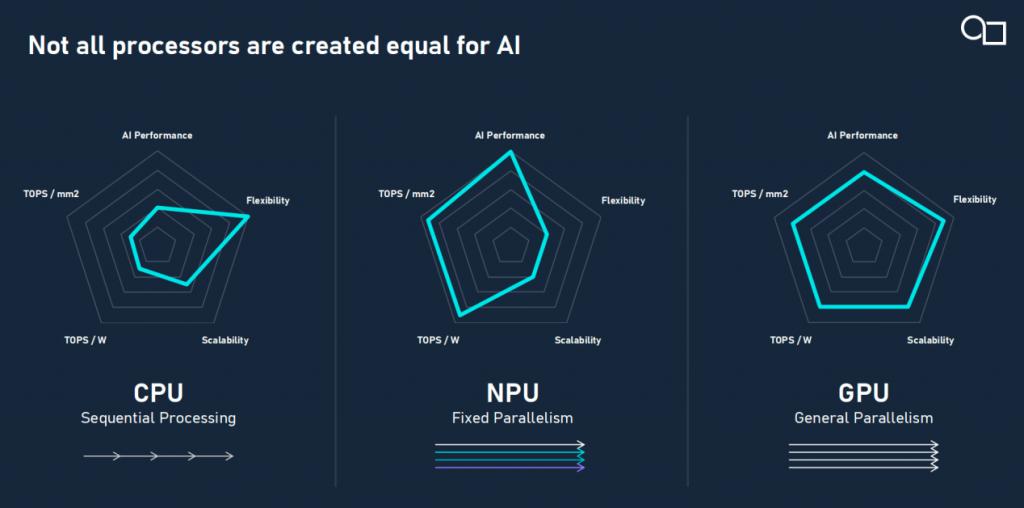
E 系列:GPU 设计的范式转变
架构革新:图形与 AI 的深度融合
E 系列 GPU 是 Imagination 产品线的一次重大飞跃,其最大的亮点,在于其对 "AI+ 图形 " 融合的系统性重构。
据 Imagination 中国区技术总监艾克的介绍,Imagination 多年来在图形处理上积累的大量技术,例如分块延迟渲染技术(TBDR)、压缩缓冲等技术,天然具备低功耗、高利用率的特点。当这些架构被用来服务 AI 推理时,展现出强大的性能密度优势。E-Series 将 AI 加速能力 " 原生 " 嵌入 GPU 体系,让 GPU 从图形引擎演进为通用 AI 处理核心。
众所周知,Imagination 的 PowerVR GPU 架构以能效著称,已在功耗受限设备中应用近二十年。然而,在硬件功耗与面积控制方面,E 系列在相同工艺节点下比前一代 D 系列实现了35% 的平均能效提升。其背后关键就在于,E-Series 引入的全新爆发式处理器(Burst Processors)技术,得益于指令调度路径压缩、本地寄存器(每个计算单元配备近 0.5MB 寄存空间)的复用机制、矩阵乘法运算单元的集成优化等架构升级。与传统 NPU 相比,E 系列无需回退至 CPU 处理 " 未知算子 ",极大提升了系统稳定性和灵活性。
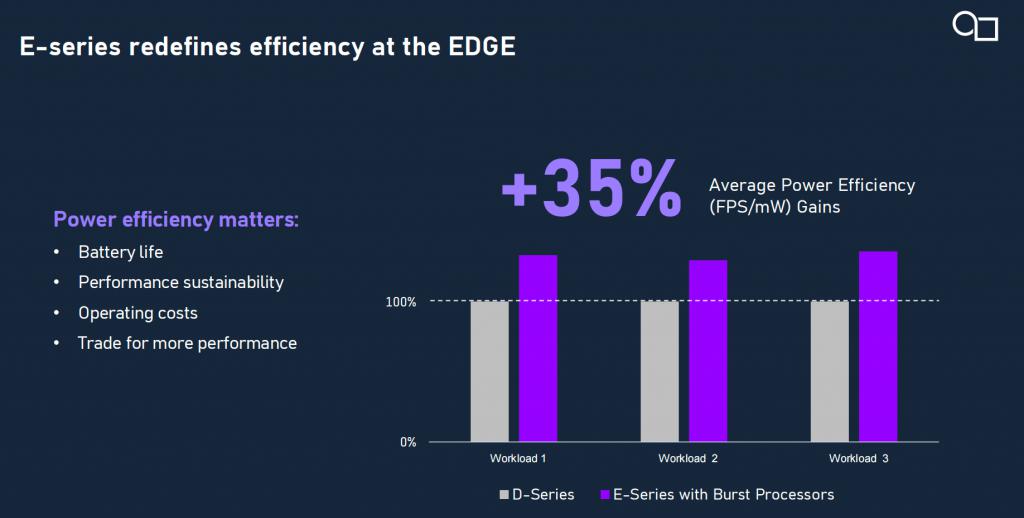
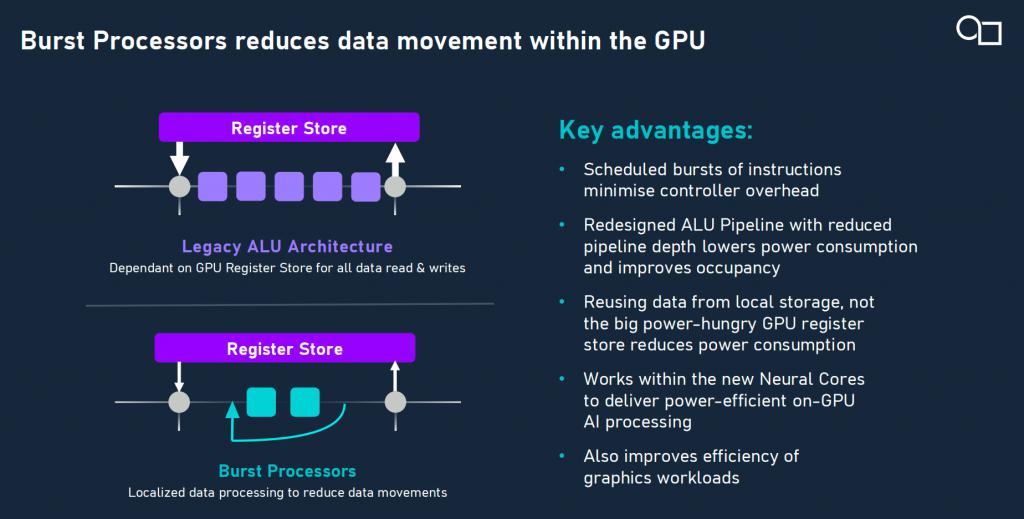
与 NPU 相比,E 系列的优势不仅体现在可编程性与灵活性上,还在于其面向未来模型演进的架构适应能力。当前市面上的 AI 解决方案多采用 GPU 与 NPU 物理隔离的架构,在数据交互、功耗效率和系统成本方面均存在短板。而 E 系列则实现了 AI 计算单元与 GPU 图形管线的深度集成:AI 算力核心与 GPU USC(统一渲染集群)共享寄存器、缓存与调度机制,打破了以往 " 各自为政 " 的瓶颈,推动图形与 AI 的真正协同。
这种设计不仅提高了资源利用率,更带来了数据路径的显著压缩,有效降低了推理延迟,尤其适合图形增强类 AI 场景:如图像超分辨率、场景理解、光照遮蔽计算、景深识别等。它还兼容 Vulkan、OpenCL 等主流计算接口,编程生态友好,具备广泛的开发者支持基础。
" 很多 NPU 在设计时只能适配当前主流模型(如 CNN),一旦未来模型发生变化(例如 Transformer 或多模态网络),现有 NPU 将无力支持,而 GPU 的编程灵活性则确保了其长期适应性。" 这一点对于生命周期长达十年以上的车规级芯片尤其重要。Imagination 发言人指出。
算力飞跃:从轻量级到多模态的全场景覆盖
在算力层面,E 系列 Neural Cores(神经核)支持 2TOPS 至 200TOPS 的 AI 算力覆盖,支持从轻量级终端到复杂多模态系统的全场景部署。4 核 1.6GHz 配置下,图形填充能力可达 400Gpixels/s,FP32 浮点运算能力 13TFLOPS,而 INT8 推理性能更是达到惊人的 200TOPS。这种单位面积下的算力密度比前代提升了 3.6 倍,远超传统 GPU 架构的性能曲线。
同时,E 系列也支持包括 FP32、BF16、FP8、MXFP4 等多种 AI 主流格式,结合 Imagination 优化的计算库与图优化编译器,开发者可通过 TVM 等框架便捷地完成 PyTorch、TensorFlow 等主流模型的部署与适配。
灵活扩展与多任务并行
在任务调度层面,E 系列支持多达 16 个虚拟机实例的运行隔离,且可通过我们的硬件虚拟化实现 AI、图形、UI 等多任务的异步并行处理。其在 Cockpit 域、娱乐域、驾驶辅助域等多种车载场景中已展现出良好的适配能力。例如,在智能座舱中,E 系列可同时承担仪表渲染与人机交互 AI 任务;在驾驶域内则实现对驾驶员状态的 AI 监控及语音交互响应。
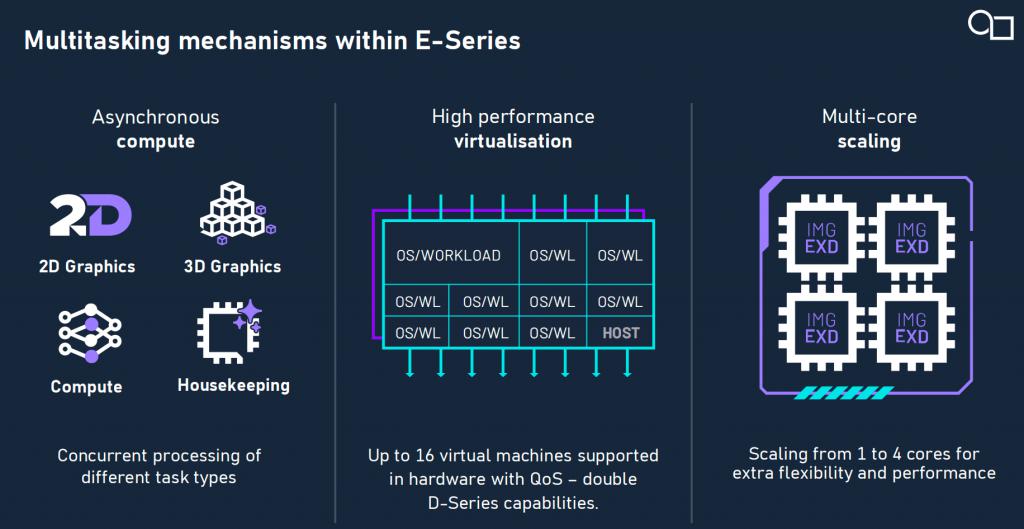
此外,E 系列支持从单核 0.25T FP32 轻量部署至多核 200T 强算力横向扩展,具备覆盖移动设备、工业终端、AI PC 乃至边缘数据中心的弹性能力,为 SoC 厂商提供从单芯片集成到异构协同的多元路径选择。
生态完备,打通从模型到芯片的部署闭环
软硬件协同是边缘 AI 落地的关键一环。Imagination 为 E 系列配套构建了完整的软件栈支持:包括数学计算库、FFT、Kernel 优化、TVM 适配、Graph Compiler、TensorRT Lite 推理链,以及多操作系统、编译器工具与调试套件。开发者不仅能完成离线模型部署,还能实现轻量级应用的在线部署及推理推送,从而支持包括自动驾驶、移动设备、工业终端等在内的多种边缘场景的动态智能需求。
值得一提的是,Imagination 在 RISC-V 生态中也扮演着关键角色。凭借其卓越的图形与 AI 能力,已与多家 RISC-V 平台客户进行集成验证,并将持续推动开源硬件与高效算力在边缘智能中的协同演进。
从实际落地来看,Imagination 已为 E 系列规划了多个子系列产品,分别面向功能安全需求的汽车域控(EXS)、消费电子(EXT)、以及 AI PC 等高性能领域(EXD)。我们可与客户协作开发配置方案,以适应从轻量级设备到复杂多模态系统的广泛需求。在 Imagination 看来,在 AI 模型迭代迅速、多模态计算需求上升的趋势下,GPU 以其灵活可编程的特性,展现出相较 NPU 更优的可拓展性与生命周期优势,尤其适用于未来十年仍需持续升级的车载平台。
首款 E-Series GPU IP 将于 2025 年秋季正式上市,目前已完成授权。汽车、消费电子、桌面及移动版本亦在同步开发中。随着正式发布日期临近,该系列产品有望在中国市场掀起一轮边缘算力升级的新热潮。Imagination 公司中国区董事长兼亚太总裁白农强调,中国是 Imagination 全球最重要的战略市场之一,公司将持续加大本地化投入,深化与本土生态的合作。
写在最后
E 系列 GPU IP 是 Imagination 技术积淀的里程碑,不仅在性能、功耗和芯片面积上实现突破,更通过架构创新,从传统图形渲染迈向通用 AI 计算。面对边缘 AI 应用的爆发式增长,尤其在轻量大模型(如 DeepSeek)快速发展的背景下,E 系列以图形渲染与 AI 推理的统一计算平台,为客户提供更高灵活性与竞争力。
AI 的未来,在云,更在边。Imagination E 系列代表着 GPU 与 AI 融合的一次范式跃迁,不仅在性能与功耗之间找到了新的平衡,更通过深度集成与软硬件协同,为边缘智能提供了一种更具扩展性、灵活性与经济性的技术解法。



