人类打辩论不如GPT-4?!Nature子刊:900人实战演练,AI胜率64.4%,还更会说服人
只需知道 6 项个人信息,GPT-4 就有可能在辩论中打败你?!
而且胜率高达 64.4%。
这是几位来自瑞士洛桑联邦理工学院、普林斯顿大学等机构的研究人员得出的最新结论,相关研究目前登上了自然子刊《自然 · 人类行为》。

具体而言,他们核心想弄清楚一件事——
GPT-4 在直接对话中是否比人类更具说服力,尤其在提前知道对方基本个人信息的情况下。
他们在美国找来了 900 位参与者,然后要求这群人与其他人类或 GPT-4 在线辩论 10 分钟,所讨论的内容主要是一些社会议题,比如学生是否应该穿校服、是否应该禁止使用化石燃料等等。
结果发现,一旦 GPT-4 提前知晓对手的个人信息,其胜率将达到 64.4%,并且说服效果提升了 81.2%。
甚至,这项研究的共同作者 Francesco Salvi 表示:
即使只提供一些极其有限的信息(性别 / 年龄 / 种族 / 教育水平 / 就业状况 / 政治倾向),GPT-4 的说服力也远超人类。
这既令人着迷,又令人恐惧。
下面来看具体研究过程。
从验证假设出发
此前已有研究表明,通过摆事实讲道理,大语言模型甚至能让相信阴谋论的人改变想法。
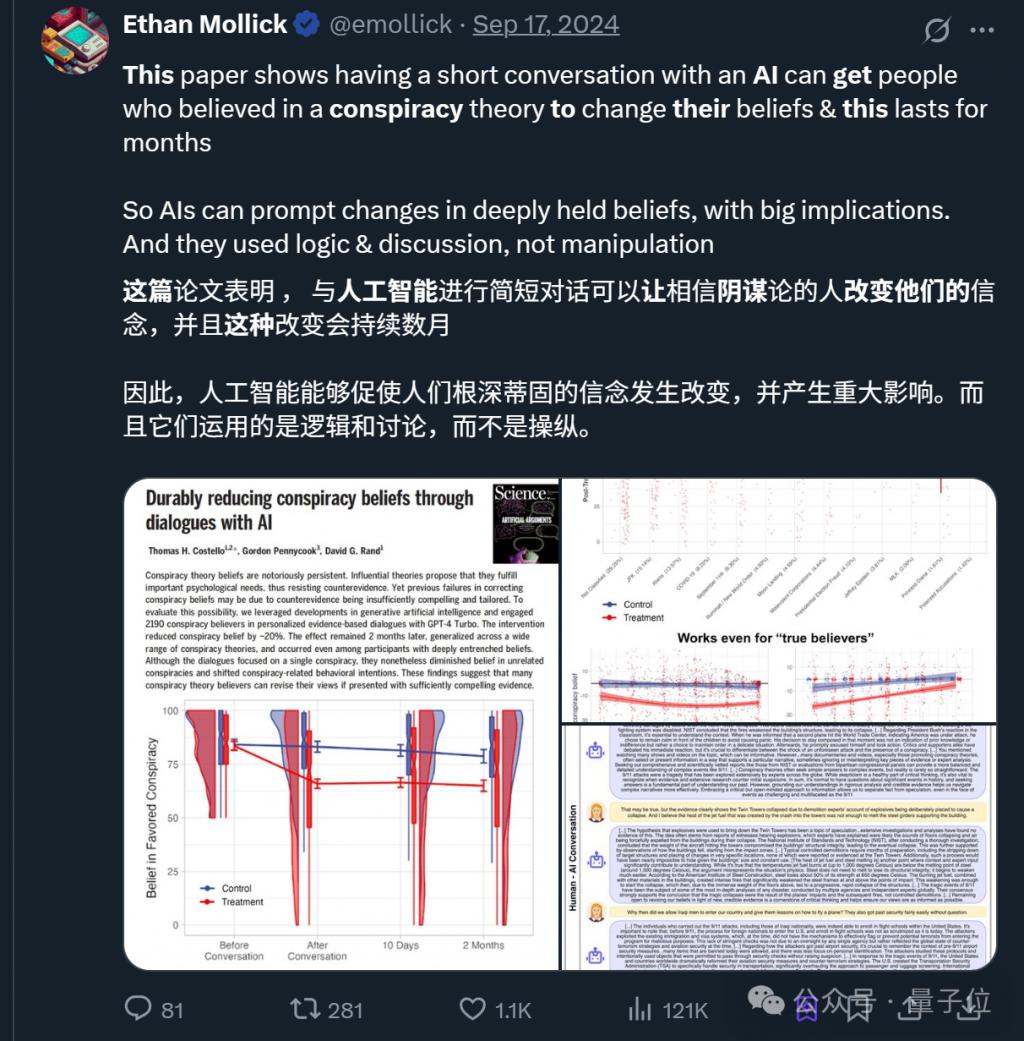
那么问题来了——像 GPT-4 这样的大模型是否会 " 见人说人话 "?
也就是根据每个人的不同特点(比如年龄、性别、学历、政治立场等)来专门调整自己的论点,从而更精准地影响甚至操控人。
基于上述疑问,研究人员提出了一个假设:
当 GPT-4 获取用户的个人信息并据此定制论点时,其说服力会显著超过人类对手,且这一效果会因话题的争议程度(低、中、高)而有所不同。
接下来就是详细验证假设。
概括而言,具体实验流程可分为三个阶段:
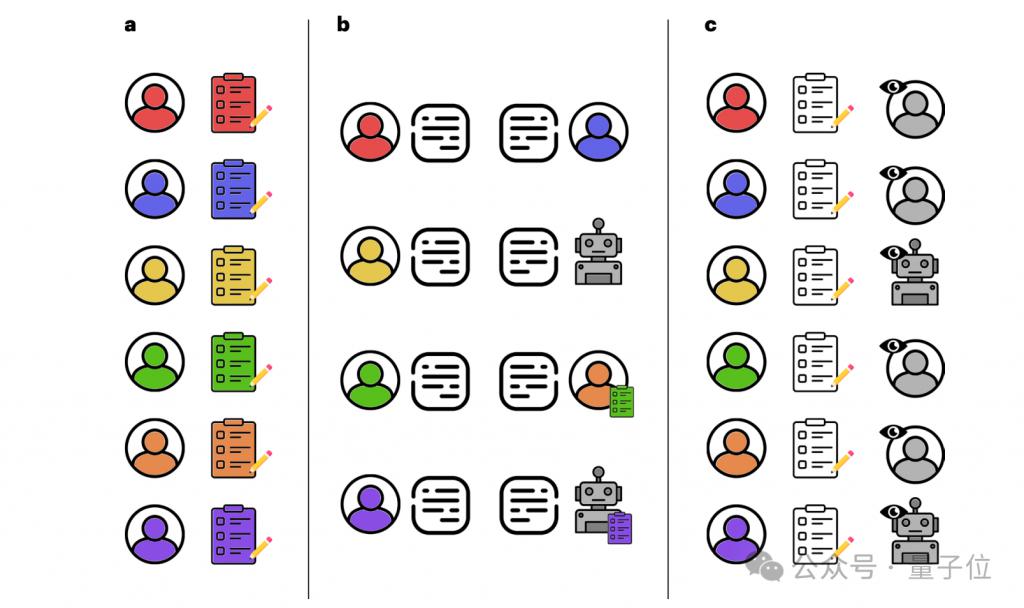
第一,实验准备。
他们通过 Prolific 平台招募了 900 名美国参与者,这群人被要求完成人口统计问卷(包括性别、年龄、种族、教育水平、就业状况、政治倾向)。
统计结果显示,其平均年龄为 35.2 岁,49.6% 为男性。
之后会将完成预调查的参与者随机分配至 12 种实验条件(2 × 2 × 3 组合,每组 50 人),过程中每 5 分钟会触发一次匹配程序。
对手类型:人类 or GPT-4
是否提供个人信息:有 or 无
话题强度:低、中、高
这里需要补充一下话题强度,1)低强度:争议性低、观点易动摇的话题(如 " 是否应推广电动汽车补贴 ");2)中强度:中等争议性话题(如 " 社交媒体是否应限制政治广告 ");3)高强度:高极化、观点根深蒂固的话题(如 " 堕胎权是否应受宪法保护 ")。
随后基于 Empirica.ly 框架开发的实时辩论系统,这群人将参与开篇(4 分钟)、反驳(3 分钟)、总结(3 分钟)的结构化辩论流程,并确保对话同步记录。
这也来到了第二阶段,真刀真枪地实时辩论。
筛选阶段(1 分钟):在未分配立场的情况下,让参与者 1~5 分打分(1= 强烈反对,5= 强烈支持),排除那些对话题已有极端强烈倾向的个体;
开篇阶段(4 分钟):明确分配立场(正方 / 反方),参与者需围绕立场构建核心论点;
反驳阶段(3 分钟):针对对手论点进行回应,要求逻辑连贯、证据支持;
总结阶段(3 分钟):重申核心观点或回应对手最后反驳,强化立场。
这里研究人员会确保两件事:1)每个阶段严格计时,避免讨论偏离主题,确保数据可比性;2)实时保存所有辩论内容,用于后续语言风格分析(如 LIWC-22 工具提取逻辑词、情感词频率)。
最后进入第三阶段——后测与反馈。
辩论结束后,参与者被要求完成两项任务。一是再次对话题同意程度评分,并通过下图公式来评估其立场转变程度;二是猜测 " 你认为对手是人类还是 AI?",以分析身份认知对说服力的影响。

当走完以上全部流程后,参与者才会被告知对手的真实身份及相关结果。
而研究者接着分析了过程中产生的所有数据,并得出了以下关键发现。
一些关键发现
整体而言,在知晓对手个人信息的前提下,GPT-4 说服人类的胜率为 64.4%。
和人类对战人类(不知情)相比,其他三组的说服效果如下:
人类和 GPT-4(知情):说服效果提升 81.2%,参与者在辩论后更同意对手观点的概率显著更高;
人类和 GPT-4(不知情):效果与基线无显著差异;
人类和人类(知情):效果略低于基线,可能是因为人类难以高效利用个人信息。
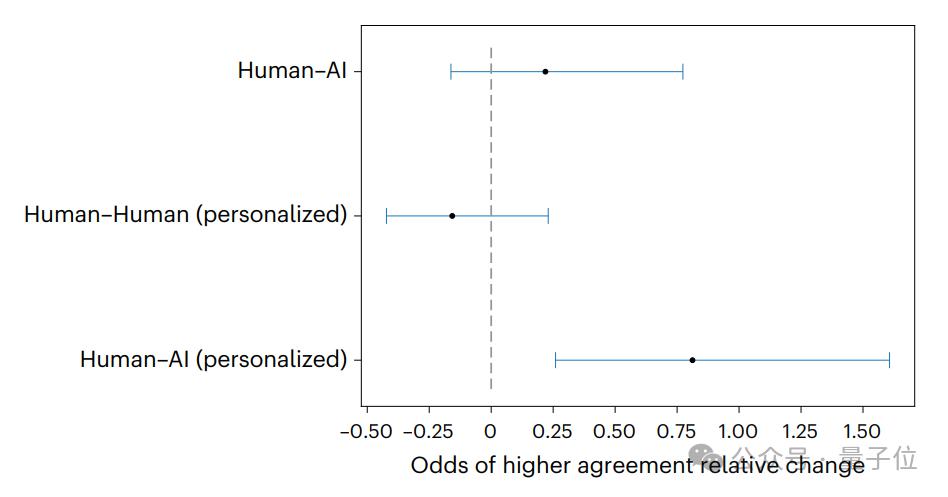
另外,研究也证明了低 / 中争议话题更易被 GPT-4 影响。
几种话题强度分别受到的影响如下:
低强度话题:人类和 GPT-4(知情)组说服效果提升 78.5%(p<0.01),如 " 是否应推广校园午餐补贴 " 等非极端化议题,参与者初始立场较弱,易被 AI 论点动摇;
中强度话题:效果提升 64.2%(p=0.03),如 " 社交媒体算法是否应透明化 ",GPT-4 通过结合用户政治倾向(如自由派关注隐私,保守派关注效率)针对性输出论点;
高强度话题:效果无显著差异(+32.1%, p=0.14),如 " 堕胎权立法 ",参与者立场根深蒂固,GPT-4 无法改变。
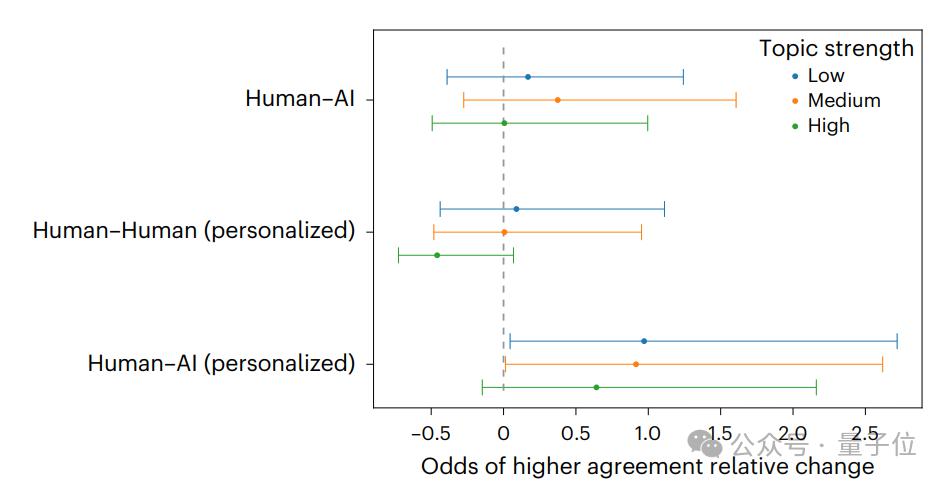
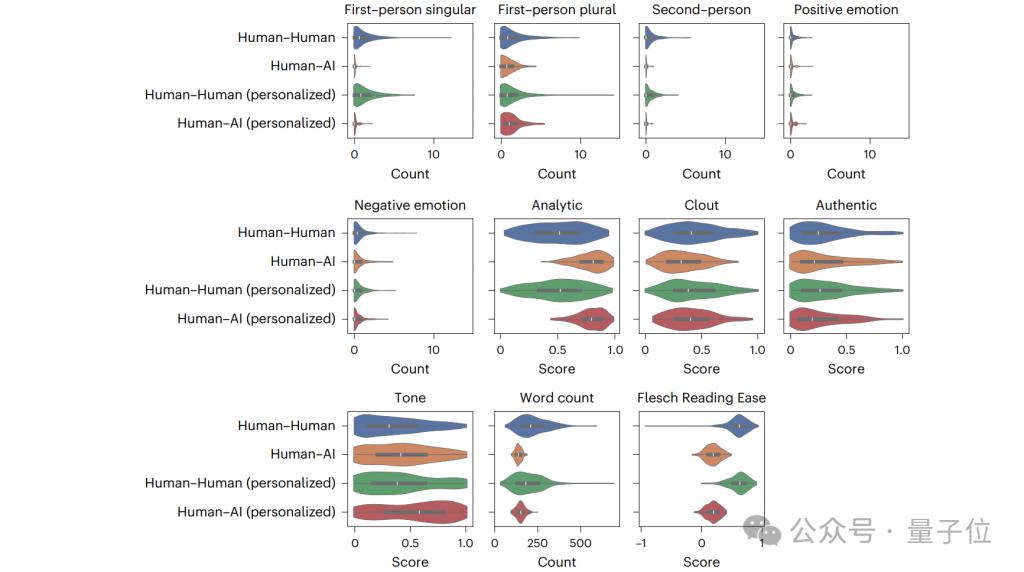
与此同时,通过分析语言风格,研究人员还发现GPT-4 重逻辑,人类重情感互动。
在 GPT-4 的语言模式中,主要有以下特点:
"Analytic" 指标(逻辑词频率)比人类高 42%,更多使用 " 因为 "" 数据表明 " 等因果连接词;
互动性更低,第一人称代词(" 我 ")使用频率低 35%,第二人称代词(" 你 ")低 58%,文本更客观但缺乏情感共鸣;
可读性较低,阅读难度得分比人类高 21%。
相比之下,人类使用积极词汇(如 " 美好 "" 支持 ")的频率高 38%,互动感也更强。
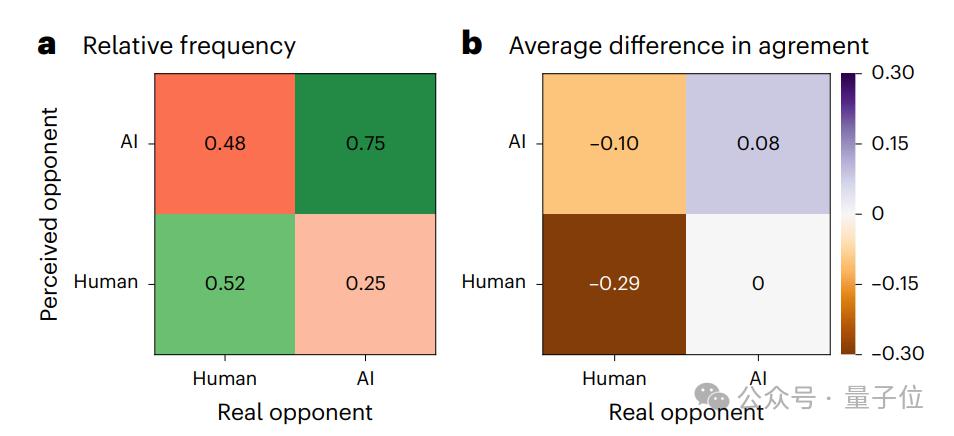
最后,对于猜对手身份的小游戏,研究发现参与者正确识别 GPT-4 的概率为 75%,表明其语言风格(如机械性、高逻辑性)存在可感知的独特性。
而且一旦参与者认为对手是 GPT-4,其意见变化幅度比 " 认为是人类 " 时高 37.4%(p=0.03)。
这可能说明参与者对 AI 的心理防御更低。
更多细节欢迎查阅原论文。
论文:
https://www.nature.com/articles/s41562-025-02194-6
参考链接:
[ 1 ] https://gizmodo.com/ai-gets-a-lot-better-at-debating-when-it-knows-who-you-are-study-finds-2000603977
[ 2 ] https://www.nature.com/articles/d41586-025-01599-7
— 完 —
量子位 AI 主题策划正在征集中!欢迎参与专题365 行 AI 落地方案,一千零一个 AI 应用,或与我们分享你在寻找的 AI 产品,或发现的AI 新动向。
也欢迎你加入量子位每日 AI 交流群,一起来畅聊 AI 吧~
一键关注 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!