中国AI,又迭代了

作者 | 荣智慧
编辑 | 向 现
唯物的中国芯片产业深度观察
5 月底,DeepSeek-R1 模型完成一次版本迭代,这次 " 小更新 " 引发了大量关注,测评显示,其整体性能逼近目前顶级模型 OpenAI o3 和谷歌 Gemini 2.5-Pro。
同一时间,华为推出参数规模 7180 亿的盘古 Ultra MoE 大模型,全流程在昇腾 AI 计算平台训练。
可以说,中国人工智能大模型的新赛季从此开启,一边是深度求索的开源低成本模式,一边是华为全栈自研的 " 可控闭源 " 模式。

集群训练系统
当 OpenAI 和谷歌强化 " 更大参数 " 和 " 更强通用性 " 时,中国 AI 大模型逐渐进入 " 拼软件 " 或者 " 拼硬件 " 的 " 极致性价比 " 时代。按照历史经验,无论技术由谁开创,只要进入 " 性价比 " 竞争阶段,中国企业的优势总是一骑绝尘。
话又说回来,到底是 " 软件定义 AI" 还是 " 硬件定义 AI",可能正决定着大模型的未来形态。

R2 还没来,R1 先迭代
千呼万唤的 R2 模型没出现,只有 R1 的迭代版本给大家 " 望梅止渴 "。
5 月 29 日,深度求索宣布其 R1 模型成功完成版本迭代,新版本为 DeepSeek-R1-0528。这个版本依然基于 2024 年 12 月推出的 DeepSeek V3 Base 模型,在后期训练阶段增加了算力投入,增强了模型的思维深度和推理能力。
此次升级后,模型的响应质量提升,在复杂推理、多步骤计算方面更准确,长文理解和生成更连贯,数学和编程等专业性输出更可靠;响应速度也有相应提升,在网页端、APP 和 API 接口中反应更快,处理超长文本输入时,延迟有所降低;对话的稳定性增强,减少了 " 遗忘设定 " 或 " 离题 " 的情况;API 和接口兼容性保持稳定,升级后,用户无需调整现有集成就可以无缝使用新版本。
DeepSeek-R1-0528 版本 / 图源:DeepSeek
最明显的变化是 " 思维链 " ——像谷歌的 Gemini 一样进行深度推理,写作的效果更加自然。
在性能方面,首先是模型的智能水平提升,在 AIME 2024(数学竞赛,+21 分)、LiveCodeBench(代码生成,+15 分)、GPQA Diamond(科学推理,+10 分)和《人类最后考卷》(推理与知识,+6 分)等多个方面实现进步;其次是编程能力提升,在 Artificial Analysis 编程能力指数中,R1 已追平 Gemini 2.5 Pro,仅次于 o4-mini(高水准版)和 o3 模型。
不过,Token 的消耗量也大幅度增加。R1-0528 在完成 Artificial Analysis 智能指数评估时消耗了 9900 万 Token,比初代 R1 的 7100 万 Token 多出 40% ——也就是说,新版 R1 的 " 思考 " 时间更长。
当然,消耗量也看跟谁比。同一个测试,Gemini 2.5 Pro 的 Token 消耗量比 R1-0528 还要多 30%。

DeepSeek-R1-0528 版本与其他模型对比 / 图源:DeepSeek
虽然 R1 升级效果已经 " 很强 ",但对于被 R2 吊足了胃口的人们来说,还不够。
根据之前各方透露的消息,DeepSeek R2 模型基于华为昇腾芯片训练,1.2 万亿参数规模,97% 的成本降幅,以及实现多模态融合——文本、图像和代码联合推理。
特别是成本断崖式下降,有希望让中小开发者首次触达顶级 AI 能力,达成 "AI 普惠 " 的中国方案。
网友的普遍想法是,R1 的小版本更新已经很惊艳,R2 到底强大成什么样子?是不是得等到国庆节才能看到?

硬核自研,国产 " 定心丸 "
华为习惯走那条最难走的路——全栈自研。在算力封锁下,硬是用自己的芯片训练出 7180 亿参数的 MoE 模型。
2021 年盘古大模型正式立项,隶属于华为云部门。盘古包含 E、P、U、S 四大系列,E 系列用于平板电脑、手机和 PC 设备,参数规模十亿级;P 系列参数规模百亿级,适合低延迟、低成本推理;U 系列的 Ultra,参数规模千亿级,能够处理复杂任务;S 系列也叫 " 超级盘古 ",参数规模万亿级,管理跨域或多任务应用等高级 AI 技术场景。
盘古大模型首页
5 月 29 日,盘古大模型 Ultra MoE 正式发布,该模型在模型架构和训练方法进行了创新设计,在昇腾 NPU 上实现 MoE 模型的全流程训练。
换个说法,就是华为 " 打个样儿 ",提供一套不用 GPU 训练千亿级大模型的方法。
在模型架构上,其采用了 Depth-Scaled Sandwich-Norm(DSSN)稳定架构和 TinyInit 小初始化的方法,在昇腾平台进行了超过 18TB 数据的长期稳定训练。此外,团队也提出 EP group loss 负载优化方法,不仅保证了各个专家之间负载均衡,也提升了专家的领域特化能力。
同时,盘古 Ultra MoE 使用了业界先进的 MLA 和 MTP 架构,在预训练和后训练阶段都使用了 Dropless 训练策略,实现了超大规模 MoE 架构在模型效果与效率之间的平衡。
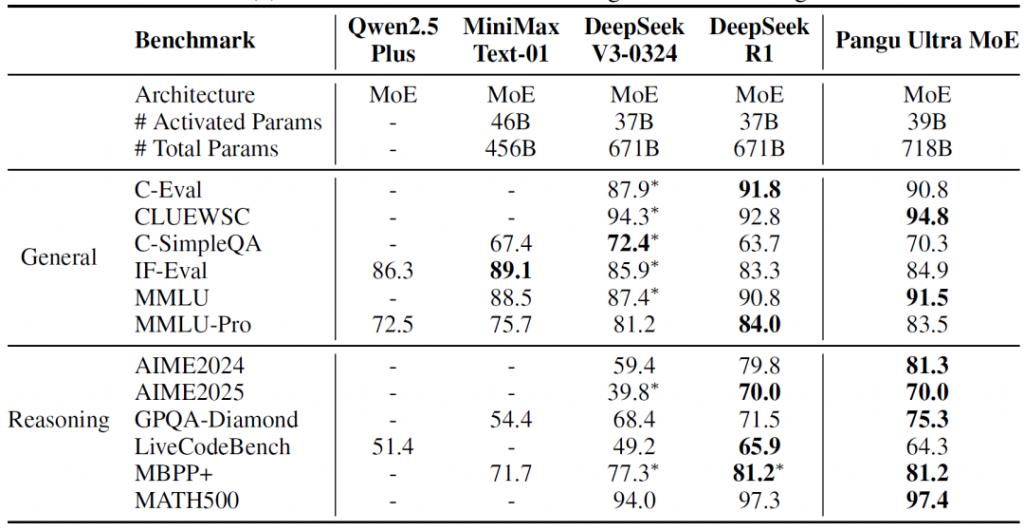
Pangu Ultra MoE 与目前主流模型效果对比
在训练方法上,华为团队首次披露在昇腾 CloudMatrix 384 超节点上,打通大稀疏比 MoE 强化学习后训练框架的关键技术。
华为在当天发布的论文中指出,该系统设计的关键在于两个部分:一是迭代难例挖掘。模型阶段性更新后,从初始的数据池中进行多回复推理,选取回复通过率在 ( 0,1 ) 的数据组成强化训练数据池,以保持推理效率最大化。
二是多能力项奖励系统。为了确保模型多能力项协同提升,数学和代码均采用了基于规则的奖励,通用奖励模型则使用 LLM-as-a-judge 的方法对生成的回复质量进行评分,并对最终的奖励进行归一化处理,保证了模型在多个能力项的综合表现。

极致突围,软硬大战?
华为盘古和深度求索常常 " 捆绑 " 出售。比如马来西亚购买中国的 AI 基础设施,核心装备就是 3000 台华为昇腾 AI 计算平台,搭载深度求索的开源模型。
但是以大模型产品作为分析对象时,二者是竞争关系,免不了有技术性的比较。
从底层架构看,深度求索主打 " 动态优化 ",华为盘古主打 " 全栈自研 "。
深度求索的核心竞争力就在于极致的工程优化,其模型架构不追求最大参数量,而是通过动态推理优化,让同一套模型在不同任务中自动调整计算资源分配。比如,在代码生成案例中,R1 可以自动识别代码片段的关键部分(循环、条件判断),动态分配计算资源,错误率也更低。
DeepSeek 的代码代写页面
华为盘古大模型走的是全栈自研的路径,从芯片到模型都是 " 自己的 "。其训练完全基于昇腾 910 系列芯片,采用 DSSN 架构。比如,在矿山设备故障检测任务中,盘古大模型能在低光照、高噪声环境下稳定运行,稳定性和可靠性更强。
从计算效率看,深度求索的撒手锏是超低成本推理,华为盘古更看重训练效率。
深度求索采用稀疏化计算和动态计算图优化方法,模型仅在运行时激活必要的神经元,推理速度提升 3 倍,而成本仅为 GPT-4 的五分之一。华为盘古更关注让模型在有限资源下达到最佳性能,像 TinyInit 小初始化技术,据悉可以让 700 亿参数的模型性能媲美千亿模型。
从应用场景看,深度求索更适合极客,做的是 " 开发者工具 ";华为盘古做的是 " 行业 AI",适配很多工业场景,比如矿山、电力、制造、气象、流体力学、核能、卫星图像优化等等。
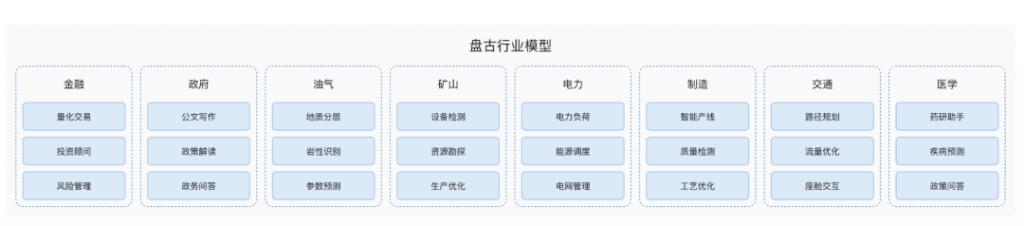
盘古行业模型
深度求索的瓶颈在于,长文本和多模态能力依然有待加强,也许 R2 可以解决这一问题,另外从 " 工具 " 升级到 " 平台 ",生态的搭建面临很大的挑战。
而华为盘古还要继续打磨硬件,单个昇腾 910 芯片性能无法匹敌英伟达 H200 的情况下,集成的性能总有达到天花板的时候,那之后又该如何提升?
可能深度求索和华为正好代表了中国人工智能大模型的两个方向,前者是软件定义 AI,用算法弥补算力的不足;后者是硬件定义 AI,用自研芯片及优化集成拉高算力。
它们虽然是两种方向,实质是同一场突围:中国人工智能在性价比战争中依然有不可小觑的优势。
值班主编 | 张来
排版 | 菲菲